Engineers have long suffered with inadequate tools. Survey after survey show that at least 60% of engineers feel that their hardware resources are inadequate for their work. But with the meteoric rise of cloud computing its easier than ever to get powerful hardware. So, what gives? The answer is that running complex technical applications in the cloud is not as simple as swiping a credit card and getting a cloud account. You need special hardware, software licenses, options to transfer large datasets, and a host of other unique requirements that only engineers have.

Fortunately, all these special requirements are now satisfied by the arrival of Cloud HPC. You can now get the benefits of High Performance Computing (HPC), with the ease of use of a workstation, and this is being powered by clouds such as Microsoft Azure.
Before we dive into why cloud computing is important to organizations, a quick history lesson is in order.
This is the story of the industrial revolutions that have taken place in the last 300 years. Back in the 18th century, the theme of the first industrial revolution was mechanization. Human labor was replaced by machines that could do the job faster, and cheaper. The technologies that powered this revolution were largely based on steam, and coal. They resulted in railways and cotton mills.
The second revolution was the age of electricity. The evolution of the mechanization of labor resulted in division of labor and specialization. The primary technologies were electrically powered mass-production tools. This was the age of Steel mills and factories.
The third revolution was one that most of us have lived through. This was the computing revolution and the key technologies were transistors and microelectronics. These technologies were driven by concepts such as Moore’s law and resulted in cheap computing.
And now we’re in the middle of a new revolution that involves fusion of the online and physical worlds. This revolution is being driven by data and intelligence and includes technologies such as IoT, AI, Smart Manufacturing, and more.
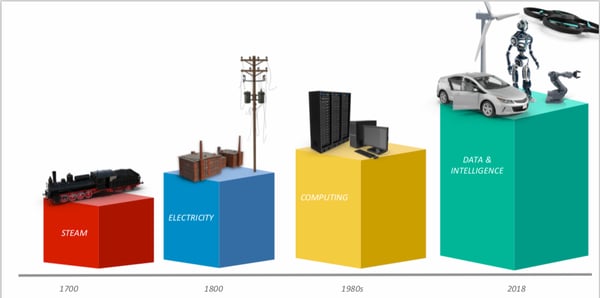
We are in the Fourth Industrial Revolution
There are a couple of interesting trends revealed when we look at these revolutions in hindsight. First - the pace of change has been quickening. In other words, the lag between these revolutions has been reducing all the time. Second - each revolution builds on the technologies of the previous one, and usually commoditizes the technologies of the previous. As an example, when the computing revolution happened, it no longer made sense to generate your own electricity. Instead you look at it as a utility. Why? because its not a high value activity any more. But more importantly, you can't take advantage of the technologies of the new revolution if you're spending your time managing the technologies of the old.
So the message is clear: if you want to take advantage of the technologies of the current revolution, you have to stop wasting time managing computing resources. To really benefit from AI, IoT and Smart Manufacturing, you need to consume computing as a utility. Thats the only way to start doing some of the exciting, higher level functions.
This Guide offers information and provides alternatives on how to benefit from some of these new and exciting technologies, using Cloud for High Performance Computing.Before we jump into the details of what and how of Cloud HPC, let's examine the why in more detail. Here are some of the common complaints of engineering organizations:

Common Customer Complaints
Organizations large and small are turning to Cloud Computing to rectify these complaints. The specific capabilities you can expect include:
...and many more.
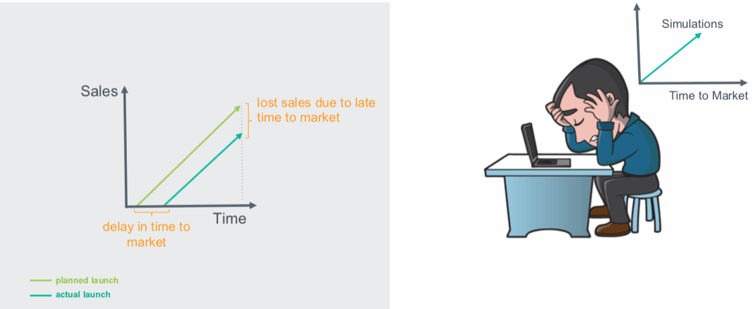
Slow Simulations = Delayed Time to Market = Lost Sales
How do all of these capabilities translate into business advantages? How do they help the executives in your organization who are responsible for the strategic operations of the business? Lets look at some of ways cloud computing can drive benefits.
Cloud computing is an approach that allows engineers and IT departments to drive their strategic initiatives instead of getting bogged down in keeping the lights on. This in turn shortens the time to develop and launch products. Cloud computing has evolved from simply improving bottom-line, to helping companies of all sizes drive top-line growth. Forrester says, "over 50% of global enterprises are looking at public cloud platforms to drive digital transformation and delight their customers."
On-premise hardware setups such as HPC clusters are inherently inflexible – they are not designed to scale up and down easily.
Hardware utilization in most companies follows peaks and valleys. For example, large projects or seasonal work drives hardware at maximum capacity, and it still can’t keep up. But in most organizations, it can take months to open a purchase order and procure and install new hardware. This means there’s no quick way to cope for unexpected peaks in demand.
And there is also inflexibility when workloads are reduced, but you still pay for the downtime. Hardware once bought must be operated and maintained whether you use it or not. Organizations should not need to commit to buying expensive hardware resources upfront in the hope that business opportunities will follow.
Cloud computing allows organizations to close the loop on IT ROI, connecting IT resources usage with revenue generated by project. Engineering managers now have impartial data to help executives clearly see which projects should be allocated more resources and which ones are not producing the desired outcomes and can be terminated.
Objective data is critical to effective resource management in downturned economic conditions.
Finding space for HPC infrastructure, investing in it, keeping it current, and maintaining ends up being time-consuming and extremely complex. And efficiently meeting demand is often not possible so the return on investment doesn’t materialize.

Types of Risk - Some Obvious and Some Not
Cloud computing provides some other benefits that are not so obvious. One such class of benefits is Risk Management. Simply put, cloud computing lets you transfer risk to your vendor for the right fee. Here are some of the risks that you can transfer:
Capacity Utilization Risk - Accurately estimating capacity is almost impossible under dynamic market conditions, and you can bet that your capacity estimate is too small, or too large. This leads to waste at one end, and lost opportunity at the other. Cloud providers can avoid this issue by spreading this planning risk over their pool of customers. The resource pool is shared across a greater number of users thereby flattening the peaks.
Development Risk - Setting up an on-premise HPC system is no trivial undertaking. But the tasks to setup simulation hardware and software offer zero competitive advantage to you. For example, if you employ your internal IT developers to setup a server, install the OS, install drivers, setup Ansys etc - these are activities that offer ZERO differentiating value to your company. The irony is that although this is a low-value activity, it is also complex. At every stage of this process something can go wrong, and you have to plan for this. There is tremendous opportunity cost to tying up your valuable resources with these complex, low-value tasks. The cloud vendor can eliminate these wasteful activities.
Adoption Risk - This is another risk that very few companies think about, but which none can afford to ignore. What if you setup your on-premise HPC simulation cluster with all the best hardware and software, and very few of your engineers end up using it? This might happen for all kinds of reasons. Maybe the engineers were not trained fast enough. Or they hated the workflow. Or found it too complicated to use. Now you're stuck with a huge amount of capital outlay that is depreciating fast. A cloud vendor can help you test the waters with a small user pool, before you expand.
Risk of Operational Failure - When you setup a shared simulation environment, you need to architect it for stability and reliability. But when you use a Cloud HPC provider, you can outsource all of that to the vendor. At last count, Microsoft Azure has 50 (count them - 50) regions. Ask yourself, can my IT team do better than that? Should they try? By adopting a global Cloud HPC solution, your risk of operational failure drops dramatically. You begin relying on the cloud provider to do the due diligence, to apply the security patches, to architect stability.
Regulatory risk - Countries and governments have unique rules, and these rules manifest themselves in various ways. One example is geo-location requirements of data. Fortunately, a large cloud provider such as Microsoft has whole divisions to ensure the rules are followed. Rather than trying to manage this risk yourself, the smart move is to outsource this risk to your provider and let them handle it for you.
Now that we've looked at the business benefits of adding cloud to your HPC setup, lets go deeper into some of the technical innovations that are driving this shift.
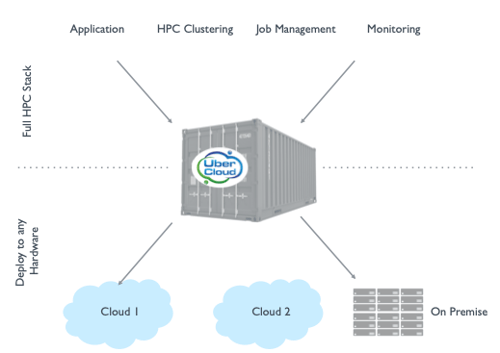
Containers Give HPC The Portability That Hybrid Cloud Demands
Containers are ready-to-execute packages of software. For example, UberCloud containers are packages designed to deliver the complete set of tools that an engineer needs. The CAE software and related tools are pre-installed, configured, tested, and are ready to execute in the cloud. Containers are also portable from server to server and to the cloud.
Container technology provides hardware abstraction, wherein the container is not tightly coupled with the server (the container and the software inside isn’t installed on the server in the traditional sense). Abstraction between the hardware and software stacks provides ease of access, ease of use, and the agility that bare metal environments lack.
Containers rely on Linux kernel facilities such as cgroups, libcontainer, and LXC which are already a part of most modern Linux operating systems. For example, the runtime components to launch UberCloud Containers are distributed via the popular open source product Docker and don’t require any additional software.
Docker is an open-source project (backed by Docker, Inc.) that automates the deployment of applications inside software containers by providing an additional layer of abstraction and automation of lightweight operating system–level virtualization on Linux. Docker uses resource isolation features of the Linux kernel such as cgroups and kernel namespaces to allow independent "containers" to run within a single Linux instance, avoiding the overhead of starting virtual machines.
Linux kernel's namespaces completely isolate an application's view of the operating environment, including process trees, network, user IDs and mounted file systems, while cgroups provide resource isolation, including the CPU, memory, block I/O and network. Docker includes the libcontainer library as a reference implementation for containers, and builds on top of libvirt, LXC (Linux containers) and systemd-nspawn, which provide interfaces to the facilities provided by the Linux kernel.
UberCloud Containers can be launched from pre-built images, which are distributed through a central registry hosted by UberCloud. Pre-built images are a popular technology for logically breaking down a physical computer environment into finer pieces. Software and operating system updates, enhancements, and fixes are made instantly available for the next container launch in an automated fashion.
UberCloud Containers come complete with:
UberCloud’s containers can operate in single node or a multi-node HPC cluster containing Intel software tools such as compilers and Intel MPI. The resulting multi-host HPC environment scales horizontally across compute nodes and contains the Intel HPC developer tools and other HPC software components optimized for the Intel Architecture.
The UberCloud multi-container environment handles the following:
Since containers don’t require a hypervisor they eliminate bottlenecks in computing and I/O to achieve bare metal-like performance, making them an ideal technology for running HPC applications. Further, each application shares components of the host operating system, making container images easier to store and transfer.
Performance tests conducted on the Intel Hyperion Cluster at Lawrence Livermore National Laboratory (LLNL) demonstrated that a medical device simulation running on the UberCloud Container achieved near bare metal solution times.
The portability of containers lets you run your HPC workload and a variety of resource providers. You can choose between large public clouds, private clouds, and hosted HPC.
Microsoft Azure is a cloud HPC platform for building, deploying and managing applications and services through a global network of Microsoft-managed and Microsoft partner hosted data centers. It provides both PaaS and SaaS services and supports many different programming languages, tools and frameworks, including both Microsoft-specific and third-party software and systems.
HPE provides a full cloud software stack with OpenStack, HPE Service Automation, CMU Cluster Management Facility, Cloud Orchestration, and more. Gain the full benefit of hybrid cloud infrastructure by identifying and implementing your right mix of public and private cloud combined with traditional IT. HPE as a Service (HPCaaS) cloud computing solutions provide simplicity, security, governance, and speed for your private, hybrid, and managed clouds.
Advania Data Centers' HPC as a Service gives you great flexibility in your HPC operations where you have access to on demand resources when they are needed for bursting.
Opin Kerfi is the IT provider and partner to the leading Icelandic companies, financial institutions, governmental agencies, healthcare and educational industries offering consultancy, implementation, training and support service.
In order to get the benefits of cloud such as flexibility and scalability, a cloud management platform is required. UberCloud can work with several Cloud and Resource Management Platforms and some of them are outlined below.
CycleCloud
CycleCloud is one of the leading software tools for creating High Performance Computing clusters in the cloud. CycleCloud makes it easy to deploy, secure and automate the running of such clusters with a simple GUI based interface.
CycleCloud includes an orchestration layer that lets you provision infrastructure in private cloud as well as public clouds such as Microsoft Azure. It also lets you encrypt data in transit and at rest and has auto-scaling features for a truly elastic cloud environment.
CycleCloud has robust usage metering, reporting and auditing that helps IT departments and individual lines of business groups track usage and spend.
UberCloud comes with native CycleCloud integration so that engineers can quickly provision application clusters from an app-store like interface.

CycleCloud and UberCloud for Cloud Management
HPC administrators are accustomed to on-premise clusters managed using a class of tools called resource managers. Some of the most popular are Univa GridEngine, IBM LSF, Altair PBS Pro. These tools are more important than ever with the advent of Cloud, and the creators of these tools have been innovating to keep up.
If you already use a resource manager, then you will not need to learn new ways because most popular resource managers are now Cloud aware. Univa GridEngine, IBM LSF, Altair PBS Pro, all tie Cloud resources to on-premise resources to manage the Hybrid environment.
Univa Resource Manager
Univa® UniCloud® enables you to setup a rules-based approach to manage workloads. UniCloud can monitor workload queues and despatch workloads to on-premise or Cloud providers based on policies defined by you.
Resource managers such as those from Univa tie HPC workloads together, abstracting the complexity of HPC workloads. This feature set it becoming quite common. IBM, Altair and others built similar features. Plus, the list of Cloud providers the resource managers support is getting longer.
Every engineer uses applications with a variety of compute requirements. Some applications require distributed memory via MPI, where others are single threaded. Workloads also differ in their need for hardware requirements. For example some workloads run faster with the aid of a co-processor.
Managing hybrid infrastructures and assigning the most appropriate resources to each workload is what resource managers are very good at. A resource manager also good at tying workloads together to form a workflow.
Univa Grid Engine
Univa Grid Engine Container Edition can speed up your HPC deployment cycles by making it easy to orchestrate and manage mixed application environments, running containers at scale and blending containers with other workloads.
For example, Grid Engine integration allows UberCloud’s production-ready containers to be pulled from UberCloud's global, private Docker registry. The UberCloud registry has containerized versions of popular engineering applications including Ansys, STAR-CCM+, COMSOL, NUMECA, CST STUDIO SUITE.
By using a workload management solution from Univa you can manage mixed application environments, running containers at scale and blending containers with other workloads. Parallel applications are preinstalled in UberCloud containers, which are then managed by Univa Grid Engine in the same way traditional HPC jobs are managed. For customers who only want to run on-premise, UberCloud can setup the required image registry in the customer’s own data center. If needed, UberCloud containers guarantee that the same software version can run on-premise and in the Cloud, with automatic version upgrades. Once an UberCloud Container is pulled from the UberCloud private registry, it is launched and managed with traditional GridEngine commands, e.g.: qsub and qstat.
One of the most important requirements of a successful HPC system is performance. Without good performance Cloud HPC is a non-starter for many organizations. Fortunately, cloud providers such as Microsoft Azure have been building up hardware capabilities that can meet these exacting needs.
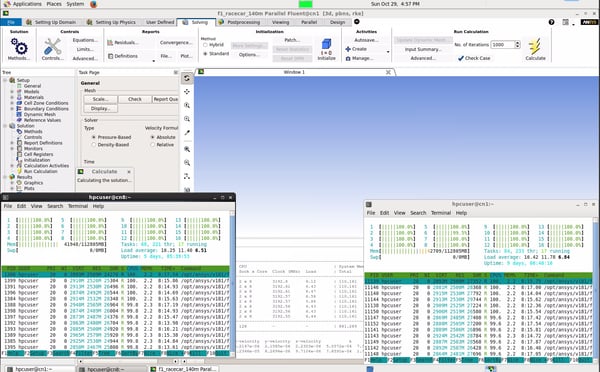
Ansys Fluent Powering Through at 100% CPU. Adding Nodes is Easy.
One of the advantages of using Cloud HPC is that you can experiment with different hardware configurations to converge on the ideal hardware price-performance. This picture above shows an Ansys Fluent Benchmark running on UberCloud. The windows at the bottom left and the bottom right show the two nodes (or servers) that form this cloud cluster. There are 32 physical cores that are being used at 100% to power through the analysis. You can continue to stack more of these nodes to build larger and larger clusters to speed up your analysis.
The following is the speedup graph of Ansys CFX on Cloud HPC running a standard benchmarks going from one node to thirty-two nodes.
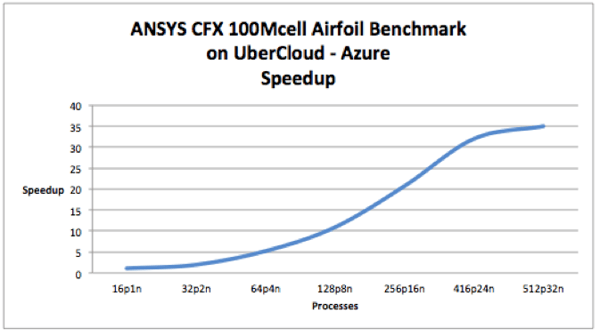
Ansys CFX Speedup from 16cores to 512cores
As the figure illustrates, the scaling from 16 processes to 512 processes is fairly smooth. Hardware scalability is gated by the performance of the network interconnect. Tightly coupled parallel applications such as CFX require substantial amounts of communication between each process in a node and also with processes spread out over multiple nodes in the network. Because of this a network with low latency and high bandwidth is required for performance. With these tests a network consisting of FDR InfiniBand interconnects and switches was used.
The following image shows a different benchmark of Ansys Fluent. The plots show the impact of InfiniBand (over Ethernet) in the scalability with increasing cores.
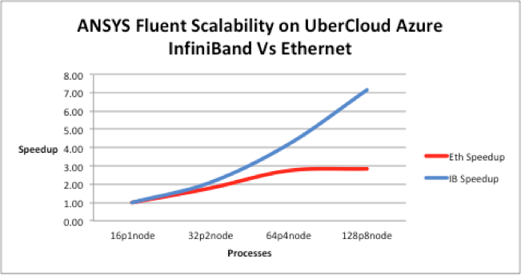
Why InfiniBand matters for Scalability
Cloud computing is a business “game changer” that drives revenue for businesses. By intelligently adopting cloud for HPC, organizations can expand the scope of their capabilities while reducing or eliminating the downsides of owning depreciating hardware assets. Its a mistake to think of Cloud as an all-or-nothing decision. In fact the ideal way to adopt this new delivery model is to take it in stages.
A good place to start is to identify a group of pilot users running an established CAE application such as Ansys. These users can explore the capabilities offered by running Ansys in the cloud, while continuing to fall back on existing hardware resources when required. As your organizations comfort with the cloud service grows, users can do more and more with cloud.
Experts universally agree on the positive business impact of cloud computing, But convincing your executives requires more. They need to clearly understand the true value of cloud computing to your organization.
In this guide you'll learn what every executive needs to know
This UberCloud white paper covers the key areas of UberCloud security in detail and discussed Azure security principles. The primary areas of security including: Physical Security, System Security, Operational Security, Application and Data Security.
The Annual UberCloud Compendium is a set of case studies relating to the world of Technical Computing. This year's collection features case studies based on 13 select UberCloud Experiments, sponsored once again by Hewlett Packard Enterprise and Intel.